Introduction
Web scraping is a powerful technique for extracting data from websites, enabling businesses, researchers, and developers to gather and analyze large amounts of information from the internet. Scrapy, an open-source and collaborative web crawling framework for Python, is one of the most popular tools for web scraping. This article delves into the essentials of web scraping with Scrapy, providing a comprehensive guide on how to use this tool effectively.
Factorial Calculator: An Essential Tool in Mathematics and Computer Science
What is Web Scraping?
Web scraping involves the process of automatically extracting data from web pages. Unlike manual data collection, web scraping uses scripts or bots to retrieve large datasets quickly and efficiently. This technique is invaluable for applications such as price monitoring, market research, data mining, and content aggregation.
Why Scrapy?
Scrapy is a robust framework designed specifically for web scraping. It is built on Python and offers numerous advantages:
- Ease of Use: Scrapy provides a high-level API that simplifies the process of writing web scrapers.
- Flexibility: It supports a wide range of use cases, from simple data extraction to complex, multi-step crawling.
- Efficiency: Scrapy is designed for high performance, making it capable of handling large-scale scraping tasks efficiently.
- Extensibility: With a modular architecture, Scrapy can be extended with custom middleware, pipelines, and extensions.
- Community Support: As an open-source project, Scrapy has a large and active community, offering extensive documentation and support.
Getting Started with Scrapy
Installation
To install Scrapy, you need Python 3.6 or higher. You can install Scrapy using pip, the Python package manager, with the following command:
pip install scrapyCreating a Scrapy Project
To start a new Scrapy project, navigate to your desired directory and run:
scrapy startproject project_nameThis command creates a new directory structure for your project, including the following key components:
- project_name/: The top-level directory for your project.
- project_name/spiders/: Directory for your spider definitions.
- project_name/items.py: Defines the data structures for your scraped items.
- project_name/middlewares.py: Contains custom middleware for modifying requests and responses.
- project_name/pipelines.py: Handles the processing of scraped data.
Writing Your First Spider
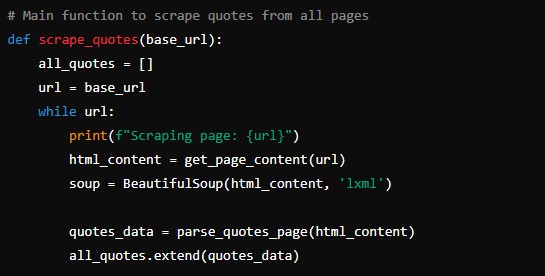
A spider in Scrapy is a class that defines how to follow links and extract data from web pages. Let’s create a simple spider to scrape quotes from a website.
- Define the Spider: Create a new file in the
spidersdirectory, for example,quotes_spider.py, and define your spider class:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)- Run the Spider: Navigate to your project’s root directory and run the spider with:
scrapy crawl quotesThis command will execute your spider and display the scraped data in the console.
Advanced Scrapy Concepts
Items and Item Loaders
Scrapy provides a convenient way to define the structure of your scraped data using Item classes. Items are simple containers used to collect the scraped data.
- Define an Item: In
items.py, define an item class for the quotes:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()- Use Item Loaders: Item loaders provide a flexible way to populate items with data. Modify your spider to use an item loader:
import scrapy
from scrapy.loader import ItemLoader
from myproject.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
def parse(self, response):
for quote in response.css('div.quote'):
loader = ItemLoader(item=QuoteItem(), selector=quote)
loader.add_css('text', 'span.text::text')
loader.add_css('author', 'small.author::text')
loader.add_css('tags', 'div.tags a.tag::text')
yield loader.load_item()
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)Middleware
Middleware is a powerful feature in Scrapy that allows you to process requests and responses globally. You can define custom middleware to handle tasks such as setting user agents, handling retries, or managing cookies.
- Define Custom Middleware: Create a middleware class in
middlewares.py:
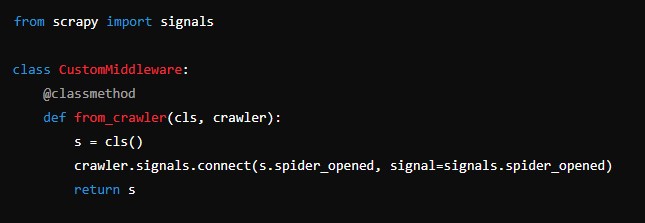
from scrapy import signals
class CustomMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
request.headers['User-Agent'] = 'my-custom-user-agent'
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)- Enable Middleware: Enable your middleware in
settings.py:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomMiddleware': 543,
}Pipelines
Pipelines are used to process the items after they have been scraped. Common uses include cleaning data, validating data, and storing data in a database.
- Define a Pipeline: Create a pipeline class in
pipelines.py:
class QuotesPipeline:
def process_item(self, item, spider):
item['text'] = item['text'].strip().replace('“', '').replace('”', '')
return item- Enable the Pipeline: Enable your pipeline in
settings.py:
ITEM_PIPELINES = {
'myproject.pipelines.QuotesPipeline': 300,
}Best Practices for Web Scraping
Respect Website Policies
Always respect the robots.txt file of websites, which specifies the rules for web crawlers. Ensure that your scraping activities do not violate the website’s terms of service.
Handle Errors Gracefully
Implement robust error handling to manage network issues, timeouts, and other unexpected events. Use retries and backoff strategies to handle temporary failures.
Avoid Overloading Servers
Use delays and concurrency settings to avoid overwhelming the target server. Scrapy provides settings such as DOWNLOAD_DELAY and CONCURRENT_REQUESTS to control the rate of requests.
Data Cleaning and Validation
Ensure that the data you scrape is clean and validated. Use pipelines to standardize and validate data before storing or using it.
Real-World Applications of Scrapy
E-commerce Price Monitoring
Scrapy can be used to monitor prices across multiple e-commerce websites. By regularly scraping product prices, businesses can track competitor pricing strategies and adjust their own prices accordingly.
Content Aggregation
Content aggregation websites gather data from multiple sources to provide a centralized repository of information. Scrapy can automate the extraction of news articles, blog posts, and other content from various websites.
Market Research
Market researchers use Scrapy to gather data on trends, consumer behavior, and market conditions. By scraping social media, forums, and review sites, researchers can gain valuable insights into public opinion and market dynamics.
Data Mining
In data mining, large datasets are analyzed to discover patterns and relationships. Scrapy can automate the extraction of data from websites, enabling data scientists to build comprehensive datasets for analysis.
Conclusion
Scrapy is a versatile and powerful tool for web scraping, offering a range of features that simplify the process of extracting data from websites. By understanding the basics of Scrapy, along with its advanced concepts and best practices, you can harness its full potential for a wide range of applications. Whether you are monitoring prices, aggregating content, conducting market research, or mining data, Scrapy provides the tools you need to gather and analyze web data efficiently and effectively.